Flujo de la información
Publicar en la web puede ser visto como un flujo de información que va desde un origen hasta un destino:
- Origen: la página web.
- Destino: los usuarios y usuarias que leeraán la información. Podrán hacerlo a través de su navegador, es decir, accediendo a una página web disponible en Internet.
Supongamos que el flujo de información de una publicación tiene su origen en unos ficheros localizados en un ordenador local, codificados en un documento HTML. Para que los lectores y lectoras puedan acceder a los documento, previamente se deben subir a un servidor web que sea accesible desde Internet.
En la actualidad, el uso de los Sistemas de Gestión de Contenidos (CMS) está muy extendido para la gestión de ficheros en un servidor web y pueden ser una fuente de sindicación de contenidos.
En este caso, el origen de los contenidos es un repositorio y, antes de ser servidos al cliente en el formato adecuado, sufren algún tipo de transformación.
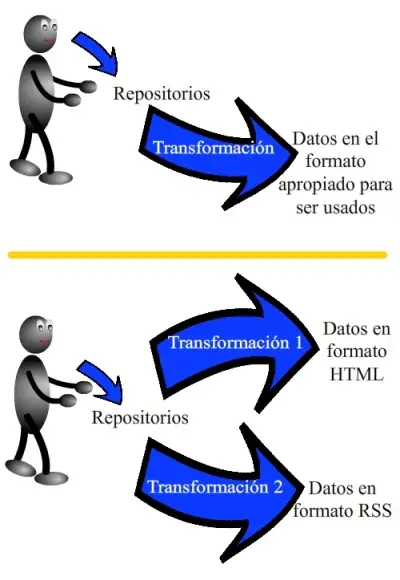
La parte superior de la figura muestra la estructura del flujo de la información en este caso. Incluso puede haber más de un repositorio.
Esta transformación puede corresponder a uno de los siguientes casos:
- Base de datos → Script (web) → Documento HTML.
- Texto plano → Página de servidor activo → Documento HTML.
- Documento XML → Transformación XSLT → Documento XHTML.
- Mente del autor/a → Bloc de notas → Documento HTML.
Al utilizar un CMS, la transformación puede replicarse. Además de tener más de una entrada de información, podríamos tener varias salidas. Por ejemplo, podemos generar tanto ficheros HTML como canales RSS.